xdbg使用tips
xdbg
xdbg有64位和32位两个版本,用来逆向不同位的程序,在编译器里面选择x64配置就是64位,我后续的代码是x86所以用的是x32dbg。
先给个我自己语言描述的个窗口功能图吧,具体作用后续展示图来体会。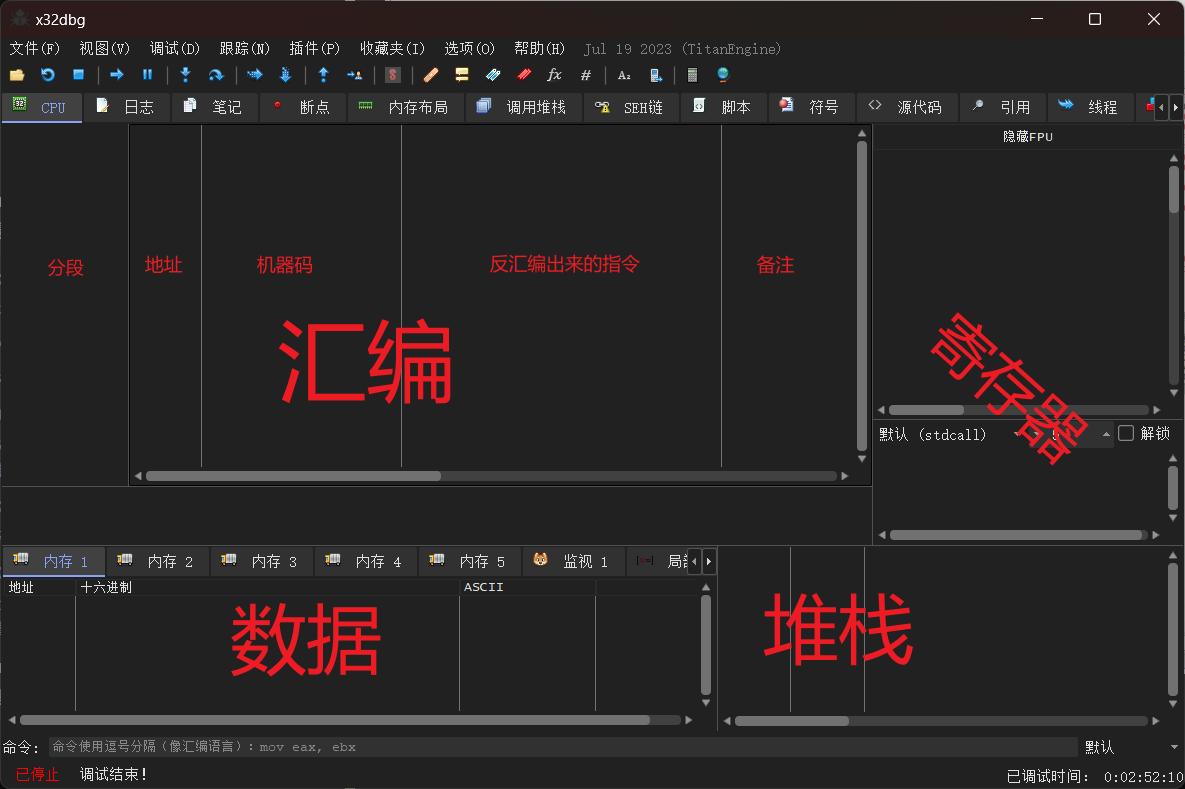
再给个后续经常用到的转到(go to)功能介绍,在编写程序时一些函数库里面的函数(比如printf,messagebox)可以直接被识别,帮助我们在0和1之间找到主函数所在。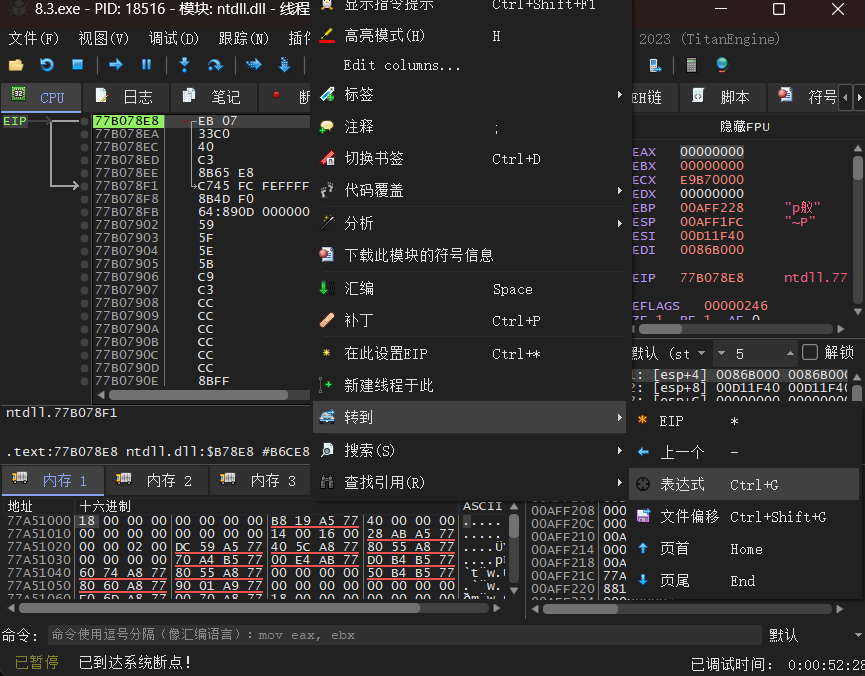
搜索messageboxw(一般messagebox默认的是w,可以在编写的时候写messageboxa并搜索messageboxa),找到后在命令处打断点并执行到断点处,然后在右下角的堆栈区找到从哪里转到这里来的,然后回车到原来的地方去,那里就是调用这个函数的地方。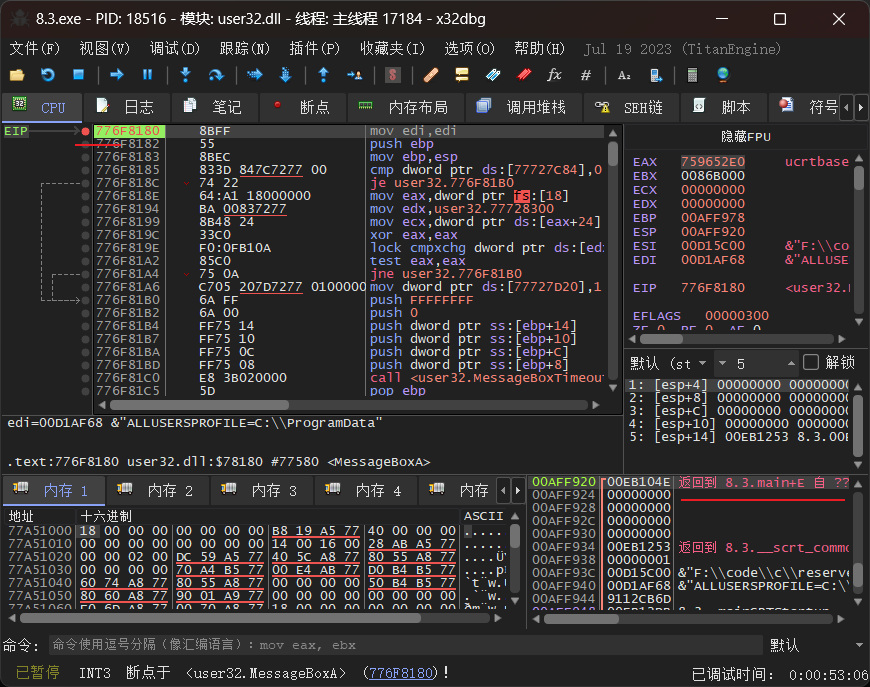
c++嵌入汇编代码
之所以我的代码都是32位正是因为64位的编译器不允许我嵌入汇编。
代码如下。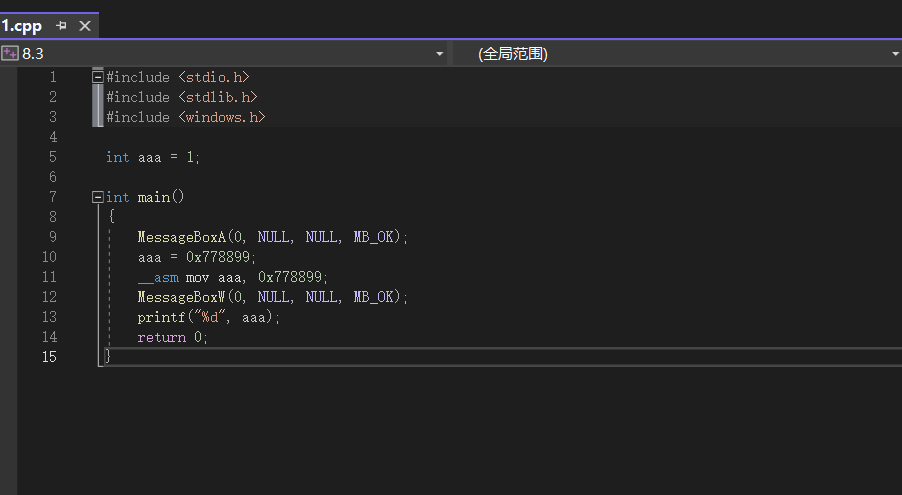
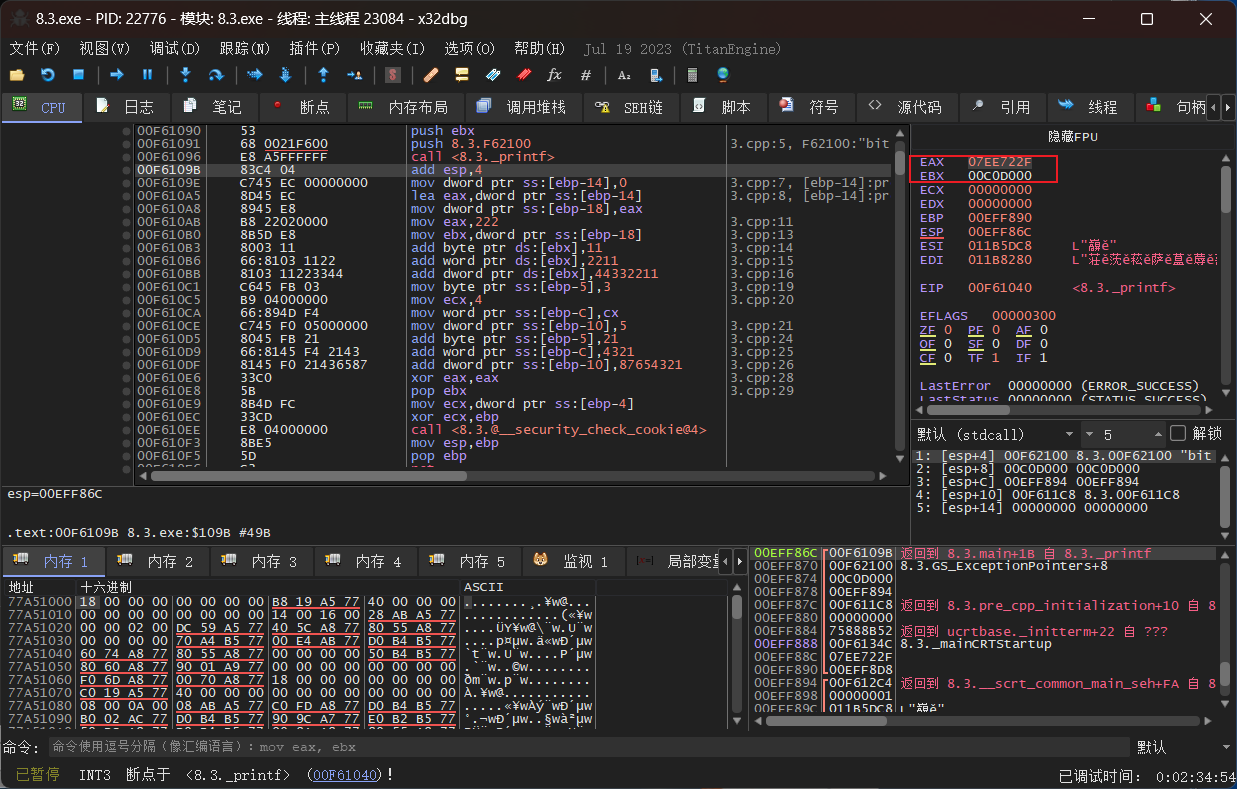
在汇编中找到主函数,这里是通过messageboxa的搜索转到的主函数,因为需要看见主函数的执行所以不是直接挑战看代码,而是让程序一步步执行到messageboxa调用的下一步来,从而回到主函数。我在代码里面为其赋值赋了两次,一次汇编一次c++,而在那个mov指令的框里逆向出来的代码和汇编代码没有差别。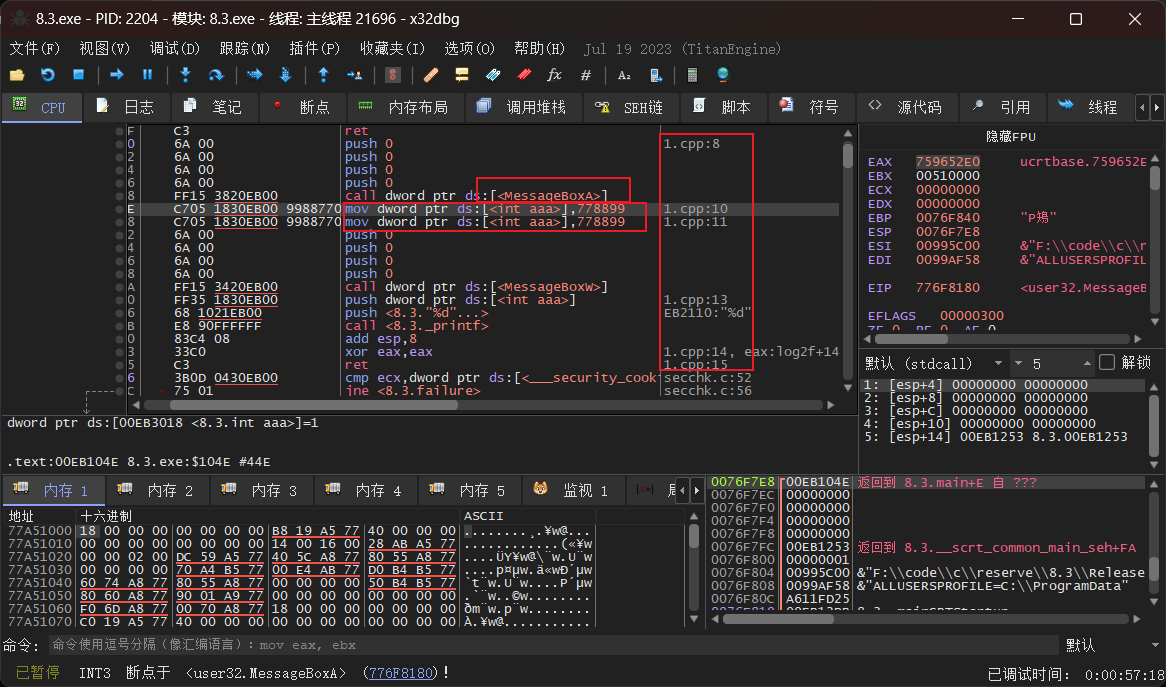
上图右边的框里面有汇编代码对应的源程序的位置,这来自于存储了调试信息的pbd文件,删除后就没有了。另外在发布软件时都不会发布debug版本以及pbd文件,所以在生成执行文件时我均采用的release。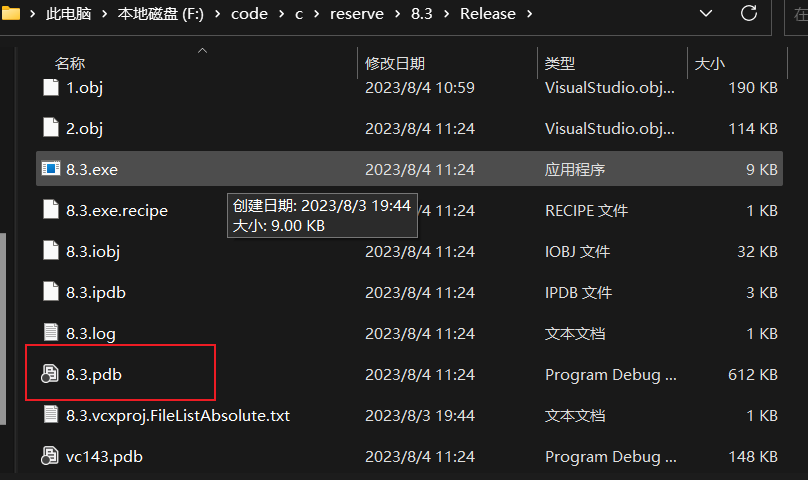
删除后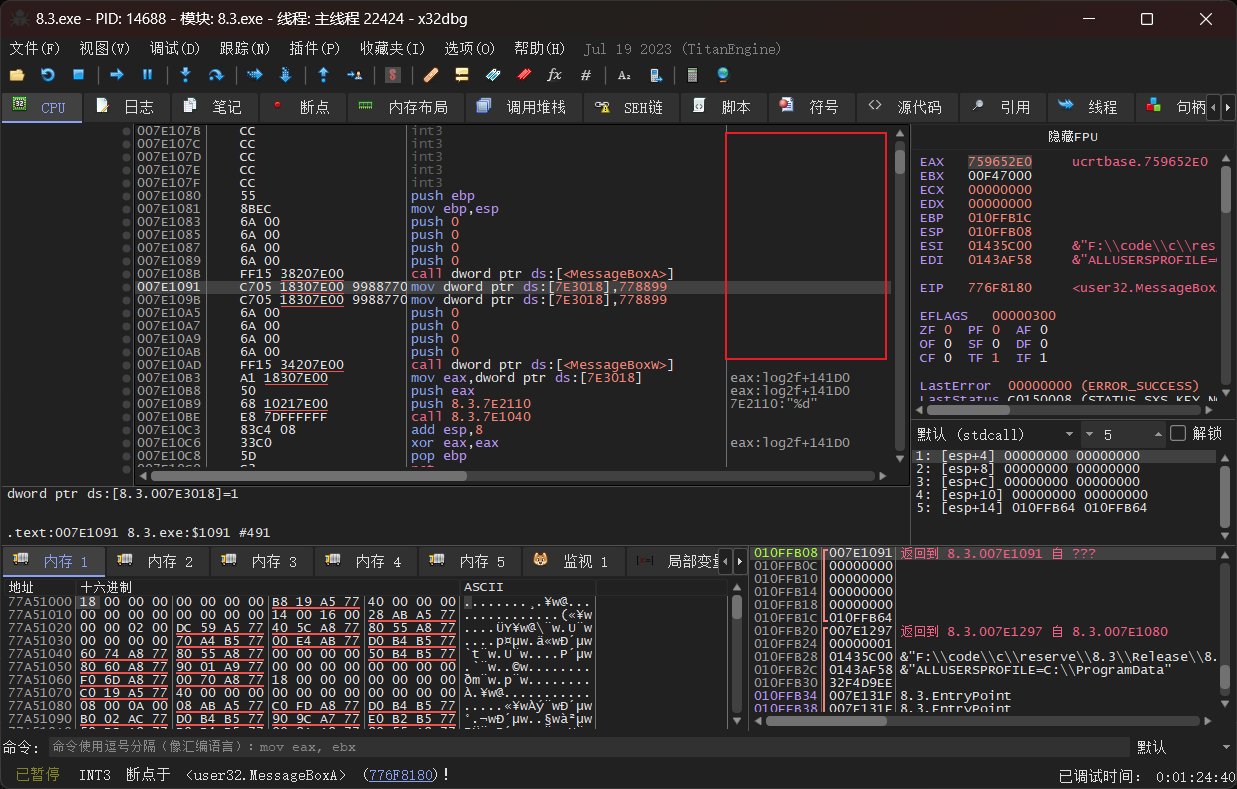
调用函数
代码如下
同样根据messagebox找到主函数所在,并找到add所在。
执行的指令所在就是主函数,在压入数值之后的执行指令就是转向了add函数,根据地址(8B1000)或者步进执行过call指令跳转到add函数。add函数也就是编译器执行加法的汇编语言流程,在add函数的末尾可以看见ret指令用于返回主函数。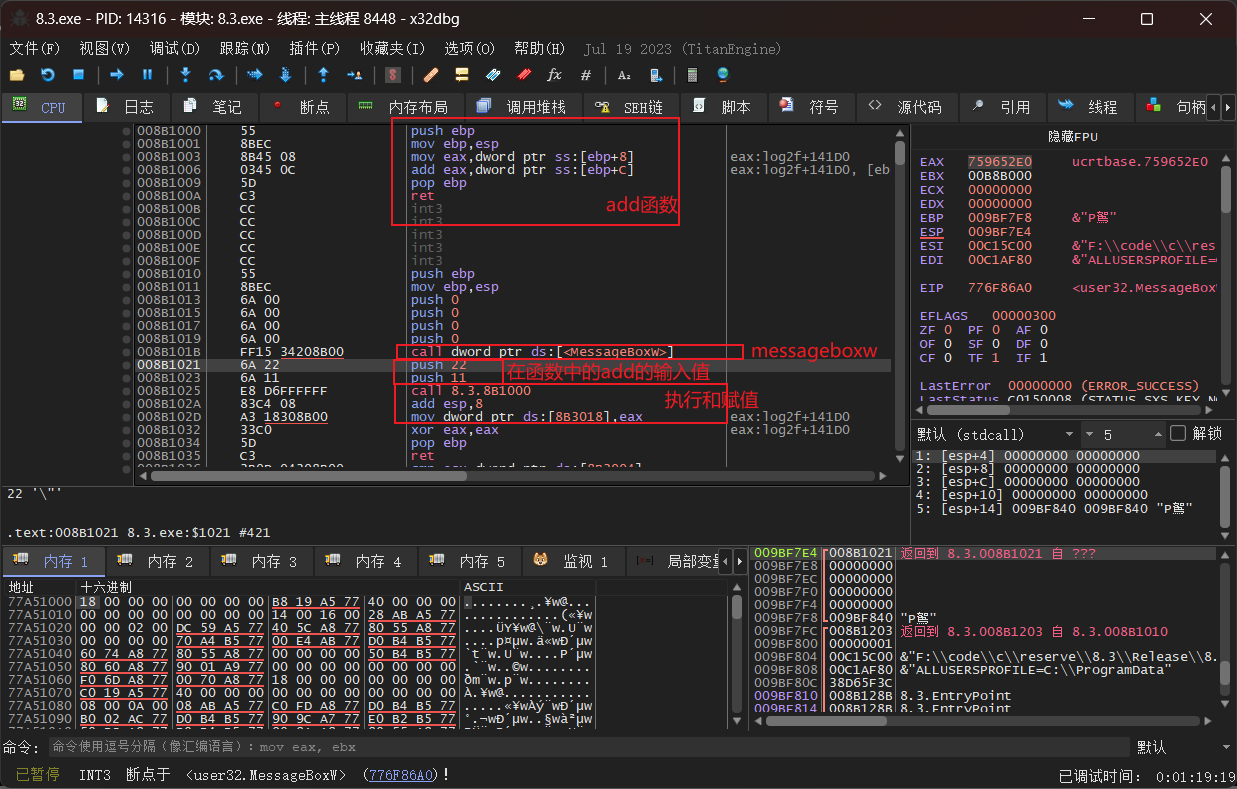
而这个结果是在关闭了编译器自带的代码优化得到的,因为这里的加法可以直接由CPU算出来,调用函数反而会减慢速度。
下图是关闭的方法和未关闭的效果。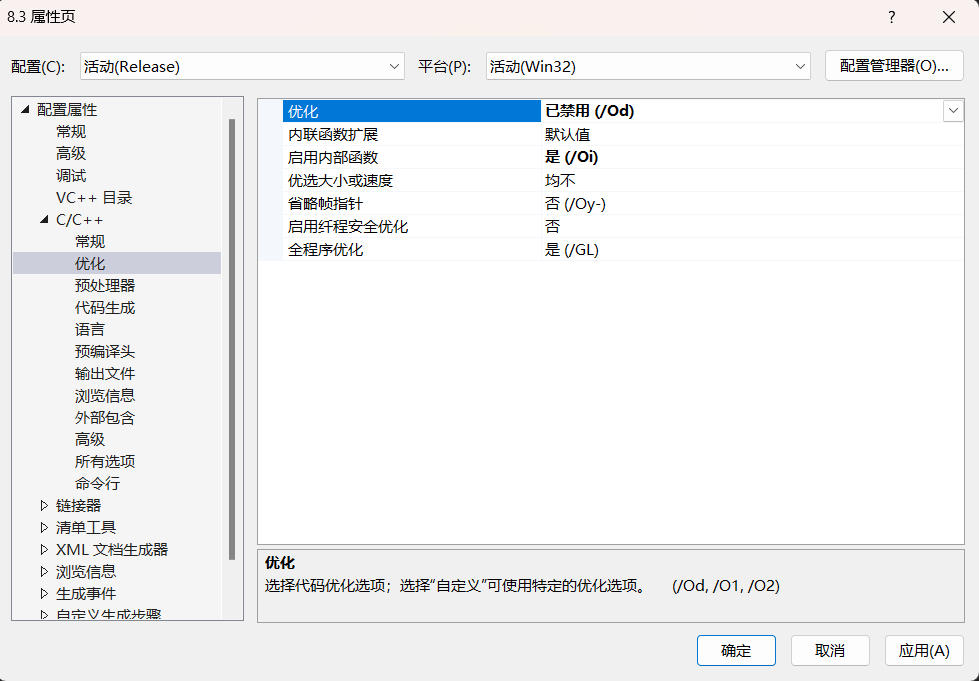
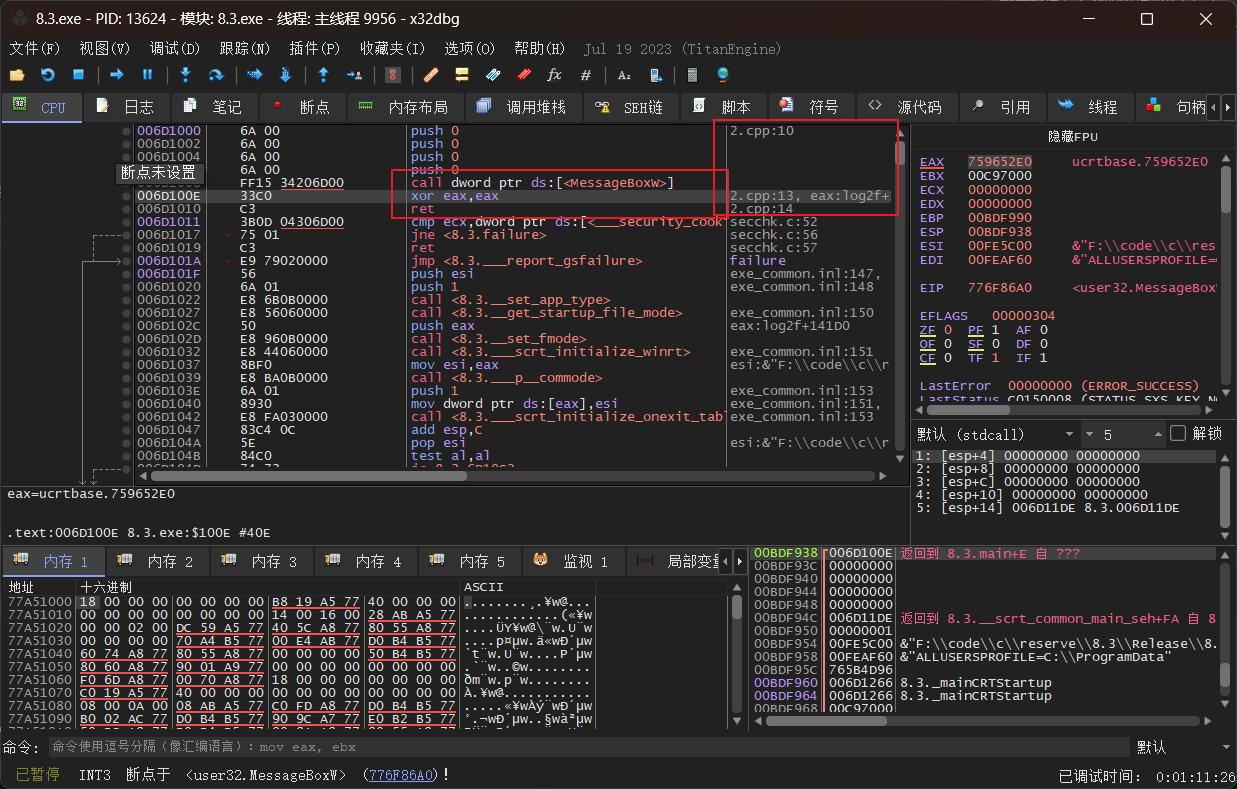
寄存器收纳的数据位数
在写代码时的int short char long代表了数据的长度,分配了内存的长度,接下来用代码来验证一下。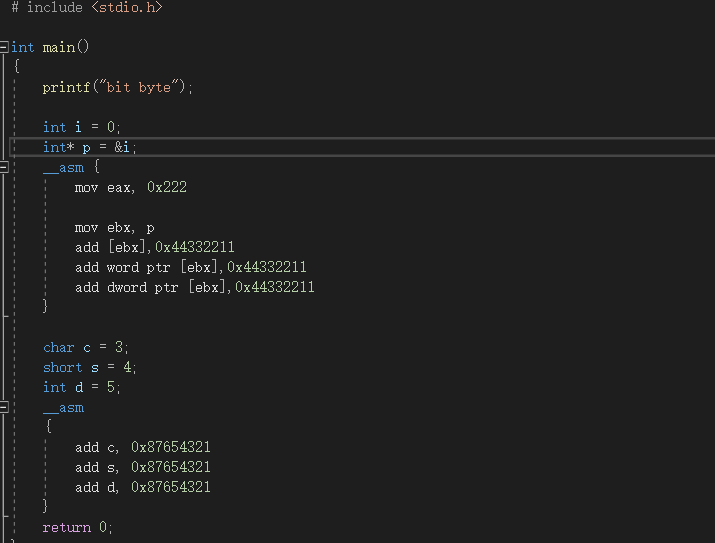
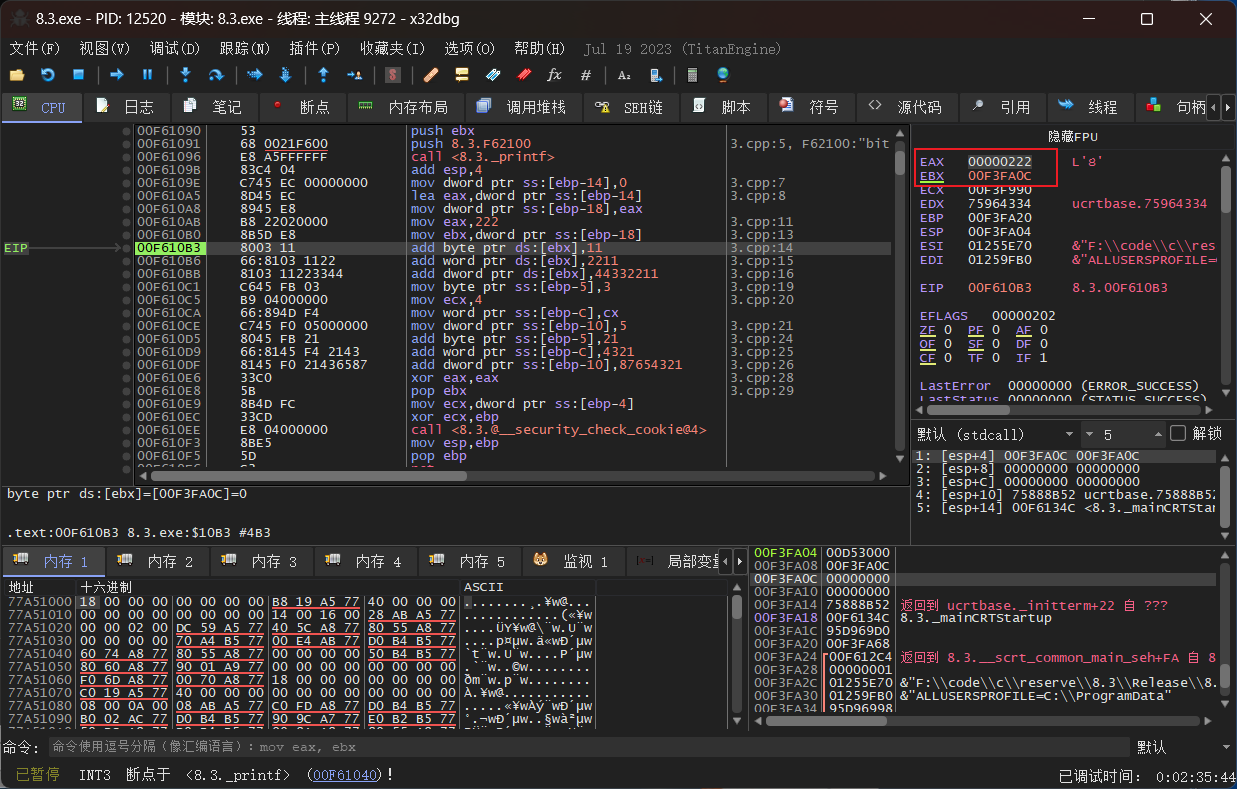
eax是32位CPU的寄存器(至少不是一字节大小的),可以储存16进制的222.在第一段汇编代码中的add,没有规定字节大小的默认为一字节所以在逆向汇编时只看得见存储成功的11,word是两字节2211,dword四字节所以44332211.这同样也是前面的代码
同样的在第二段汇编代码中,因为赋值的变量在之前用int等定义了所占内存大小,所以成功存储的大小仍然不超过该大小。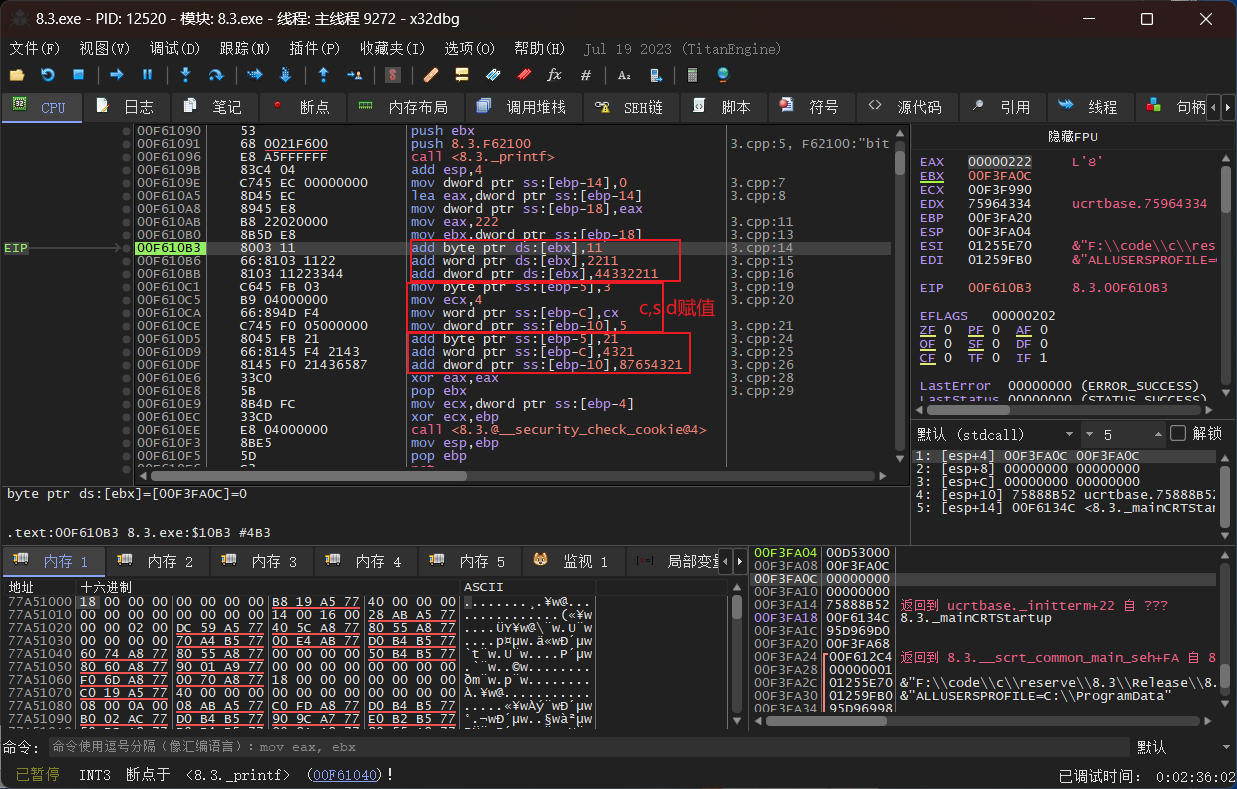
顺便也看一下第一段汇编代码里面对寄存器内部数据的改变,也就是存储222的eax和存储地址的ebx。