buuctf reverse板块部分wp的第三弹,持续更新ing
level 1
看文件然后甩进ida
进门就是flag进去看一眼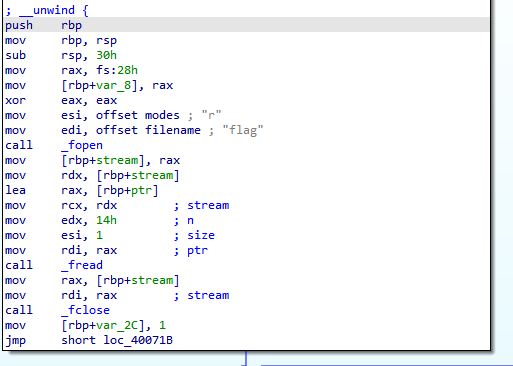
可以看见是将flag.txt文件处理了一下,那么output.txt文件反向操作就可以还原flag了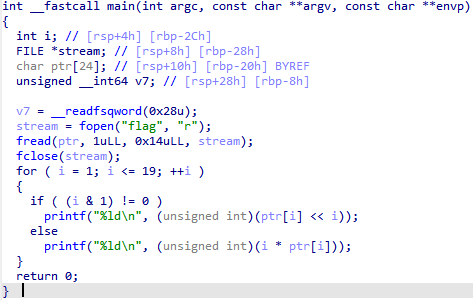
ctf2020{d9-dE6-20c}
re
看一眼有没有壳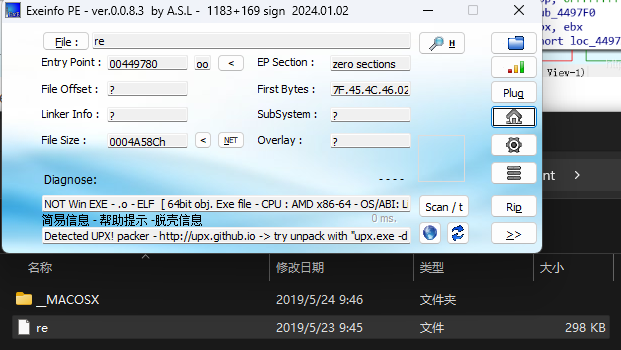
upx 脱一下
ida看一下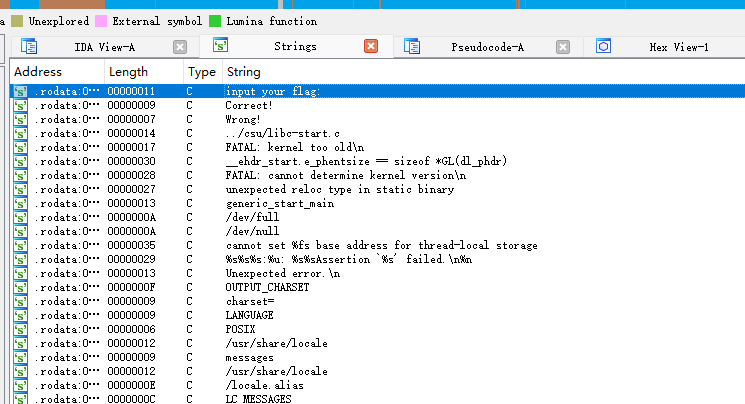
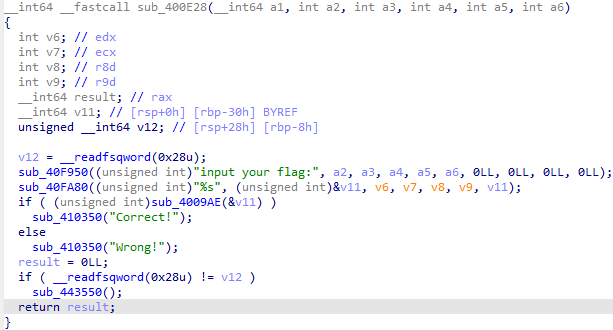
根据判断的逻辑进入sub_4009AE看一下
按照这个逻辑反过来求a,第七位没给只能爆破
flag{e165421110ba03099a1c039337}
CrackRTF
照例扫一眼,没壳,32位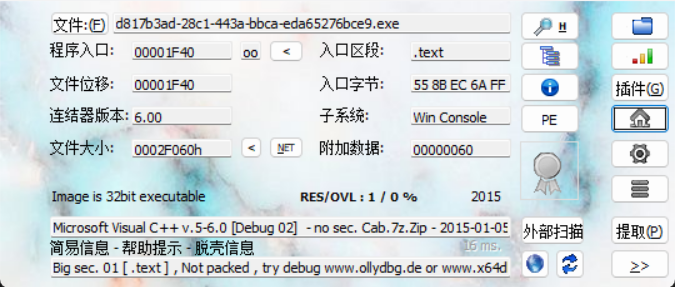
看一眼程序,显示需要输入东西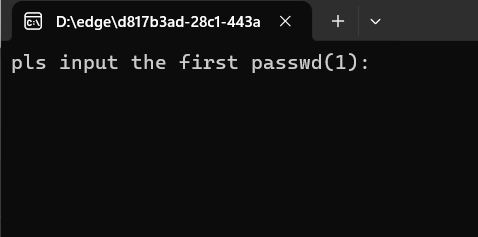
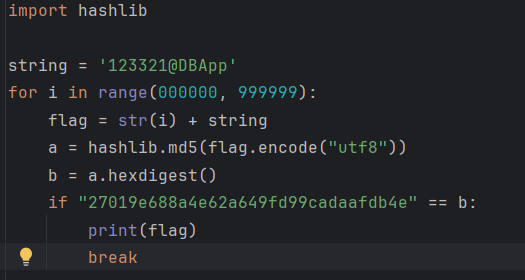
进ida看看,以下图片是分析发现第一段是6位进行了sha-1的加密
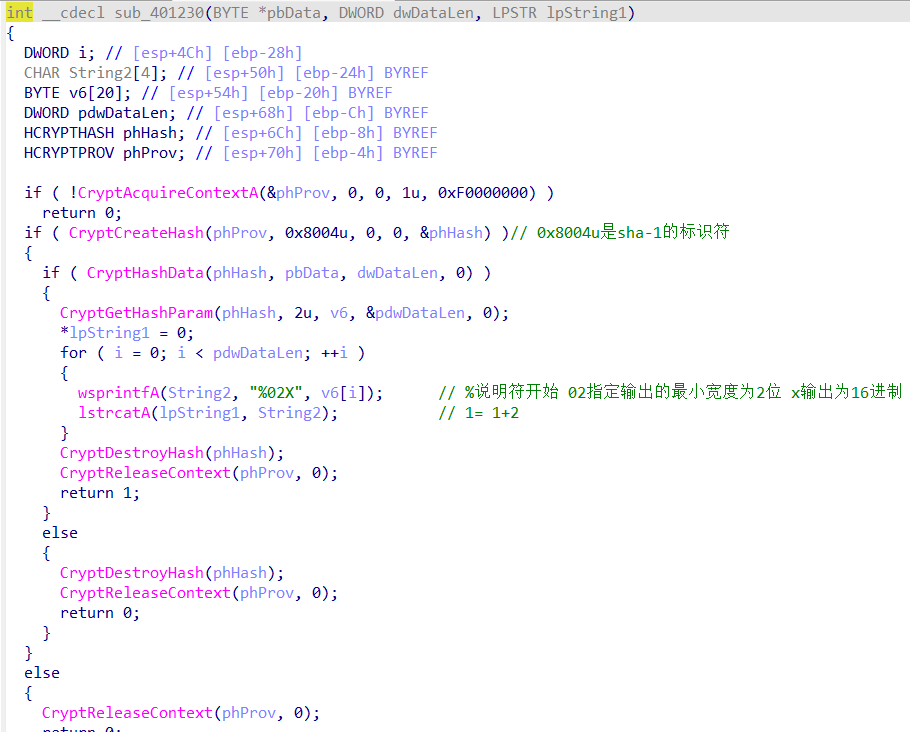
根据加密结果进行爆破
import hashlib
string = '@DBApp'
for i in range(100000, 999999):
flag = str(i) + string
a = hashlib.sha1(flag.encode("utf8"))
b = a.hexdigest()
if "6e32d0943418c2c33385bc35a1470250dd8923a9" == b:
print(flag)
break
结果为123321@DBApp
继续分析后面的,发现是md5,尝试故技重施,失败了
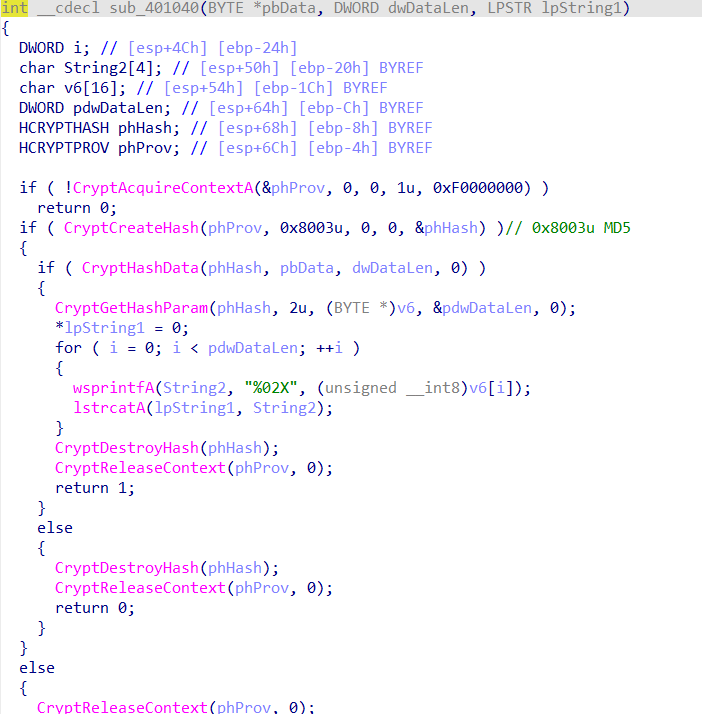
继续往后分析看见另一个40100F,整个函数其实是将一个长度为6的字符串写入了rtf文件,由于从开头开始写入的其实写入以后的内容就是rtf的头文件(虽然我去搜出来的是rtf但是由于长度为6而我自己去看也确实是rtf1)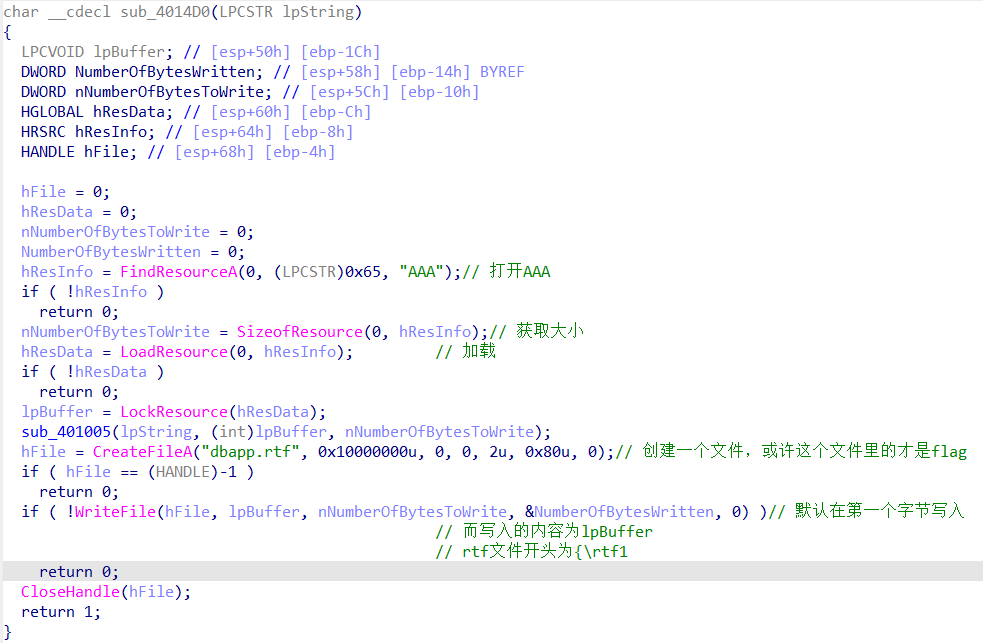
在写入之前的处理如下图,其实是将AAA的开头和需要的密码异或得到rtf头文件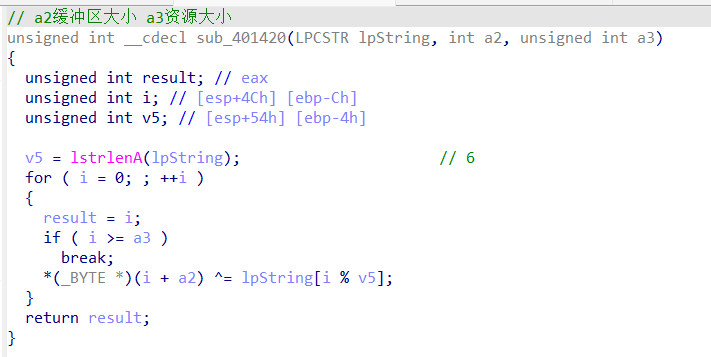
AAA的开头可以用工具看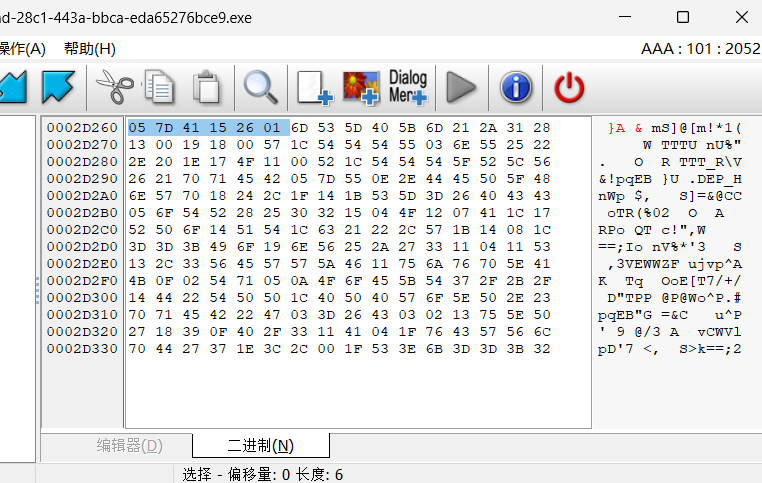
rtf = "{\\rtf1"
c = [0x05,0x7D,0x41,0x15,0x26,0x01]
result = ""
for i in range(0,6):
result += chr(ord(rtf[i])^ord(chr(c[i%6])))
i += 1
print(result)
可得为~!3a@0
而前面我们已经发现了在整个程序结束最后一步,这个程序会生成一个rtf文件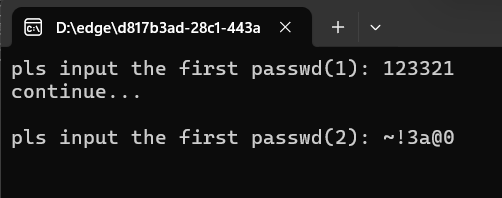
最后得到Flag{N0_M0re_Free_Bugs}
easyRE
是elf文件进ida看一眼,这里圈起来的两个函数进里面去看都很长,我们稍微猜一个这是啥意思
在if里面对v14进行了处理,可见v14里面是有内容的,黄色那个也不像是随便填充0之类的,应该是读取了某些东西然后写入了v14。然后继续看红色的,这里一个if一个for都调用了红色的函数,作为循环的次数,那么大概率是获取长度的函数。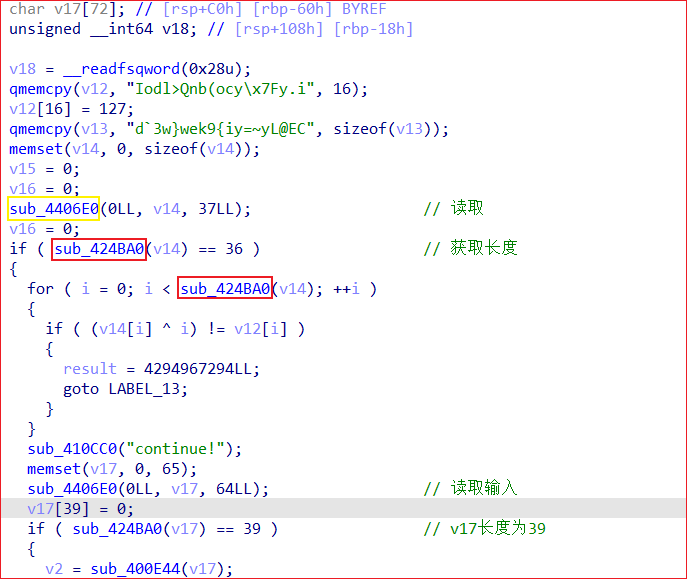
既然都知道了那么看见喜闻乐见的异或符号就可以开始写代码了
a = "Iodl>Qnb(ocy\x7Fy.i\x7f"
b = "d`3w}wek9{iy=~yL@EC"
c = a+b
flag1 = ""
for i in range(0,36):
flag1 += chr(ord(c[i]) ^ i)
print(flag1)
得到Info:The first four chars are "flag"
继续往后看可以发现400E44这个函数一直重复对一串字符进行加密
进来看可以发现这应该是一个base64加密,可以写一个对字符串重新解密的代码,看了一些wp解密以后是网址,而我的代码一直报错,所以还是继续往后看

往后看可以发现那串off_6cc090后面还有一串有标注的内容byte_6cc0a0,交叉引用去看看这一串的函数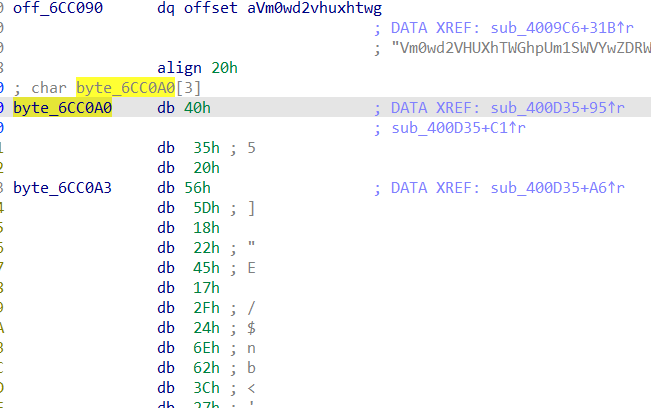
第一个红框处,发现在进行判断第一个处理后为f第四个处理后为g,回忆一下之前看见的那个info,可以猜测这个应该就是所谓的那个前四个字符是flag。而后面第二个红框进行处理的时候,v4已经经历过一次异或了,所以第二次的异或并不是flag,而是和6cc0a0这里连续四个异或以后的再异或的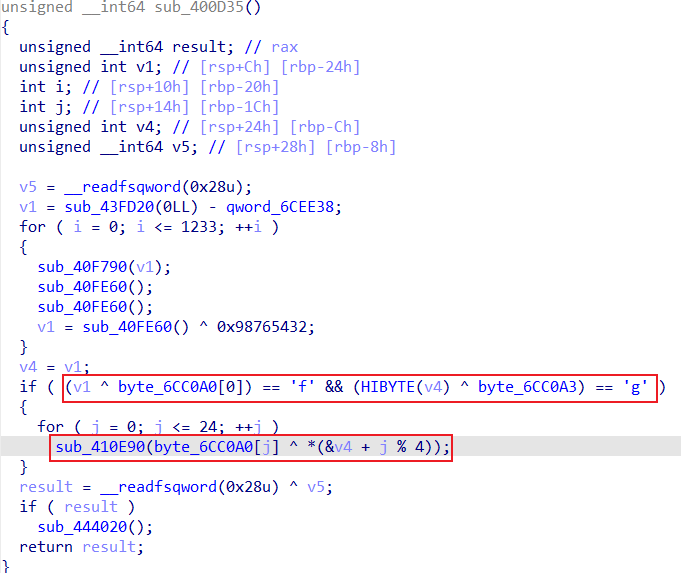
a = [0x40 , 0x35, 0x20, 0x56, 0x5D, 0x18, 0x22, 0x45, 0x17, 0x2F, 0x24,
0x6E, 0x62, 0x3C, 0x27, 0x54, 0x48, 0x6C, 0x24, 0x6E, 0x72,
0x3C, 0x32, 0x45, 0x5B]
flag1 ="flag"
b = ""
flag2 = ""
for i in range(0,4):
b += chr(ord(flag1[i]) ^ a[i])
for i in range(0,len(a)):
flag2 += chr(a[i] ^ ord(b[i%4]))
print(flag2)
得到flag{Act1ve_Defen5e_Test}
Transform
没壳,64位,直接来看函数
在很经典的异或之前先有一次赋值,只需要拿到40f040和40f0e0就可以写代码了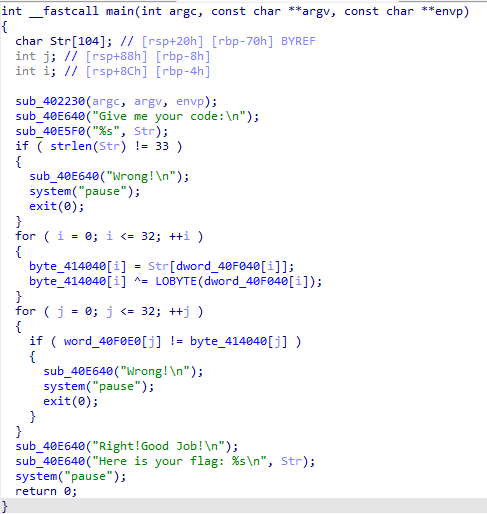
需要注意的是其中有一次取低地址,但是其实不需要多余的操作,因为那个地方是把原本的内容按照两字进行读取,而本身的偏移量仍然是一字的,而在内存中低字节放在前面,所以其实取低字节和正常的取偏移量是一样的
如下,flag为MRCTF{Tr4nsp0sltiON_Clph3r_1s_3z}
byte_414040 = [0x09, 0x0A, 0x0F, 0x17, 0x07, 0x18, 0x0C, 0x06, 0x01,
0x10, 0x03, 0x11, 0x20, 0x1D, 0x0B, 0x1E, 0x1B, 0x16,
0x04, 0x0D, 0x13, 0x14, 0x15, 0x02, 0x19, 0x05,
0x1F, 0x08, 0x12, 0x1A, 0x1C, 0x0E, 0x00]
end = [0x67, 0x79, 0x7B, 0x7F, 0x75, 0x2B, 0x3C, 0x52, 0x53, 0x79,
0x57, 0x5E, 0x5D, 0x42, 0x7B, 0x2D, 0x2A, 0x66, 0x42, 0x7E,
0x4C, 0x57, 0x79, 0x41, 0x6B, 0x7E, 0x65, 0x3C, 0x5C, 0x45,
0x6F, 0x62, 0x4D]
# 初始化 flag1 和 flag2
flag1 = [0] * 33
flag2 = [0] * 33
# 反转操作:取消 XOR 操作并构建 flag1
for i in range(len(byte_414040)):
flag1[i] = byte_414040[i] ^ end[i]
for i in range(len(byte_414040)):
flag2[byte_414040[i]] = flag1[i]
for i in range(33):
print(chr(flag2[i]),end="")